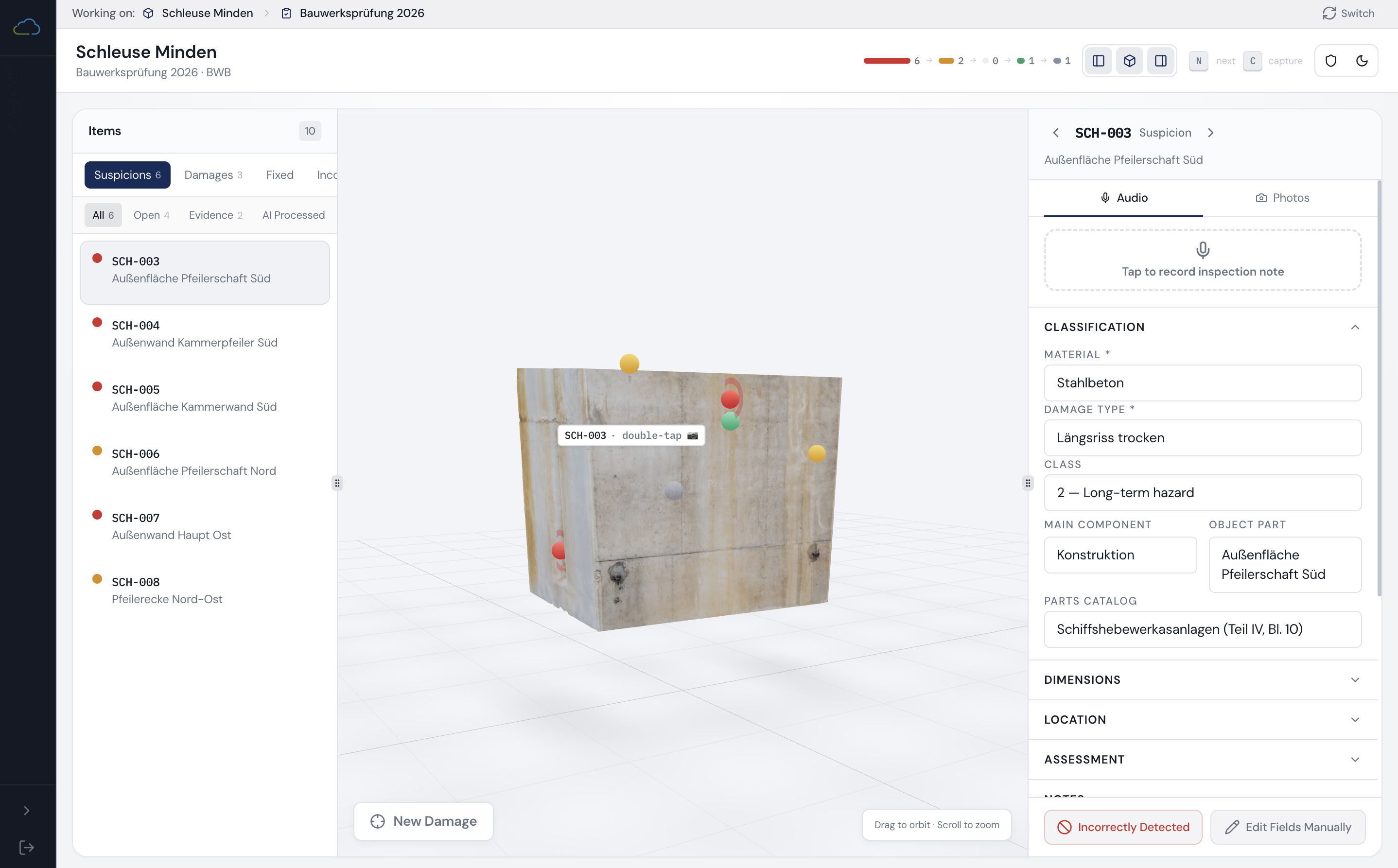
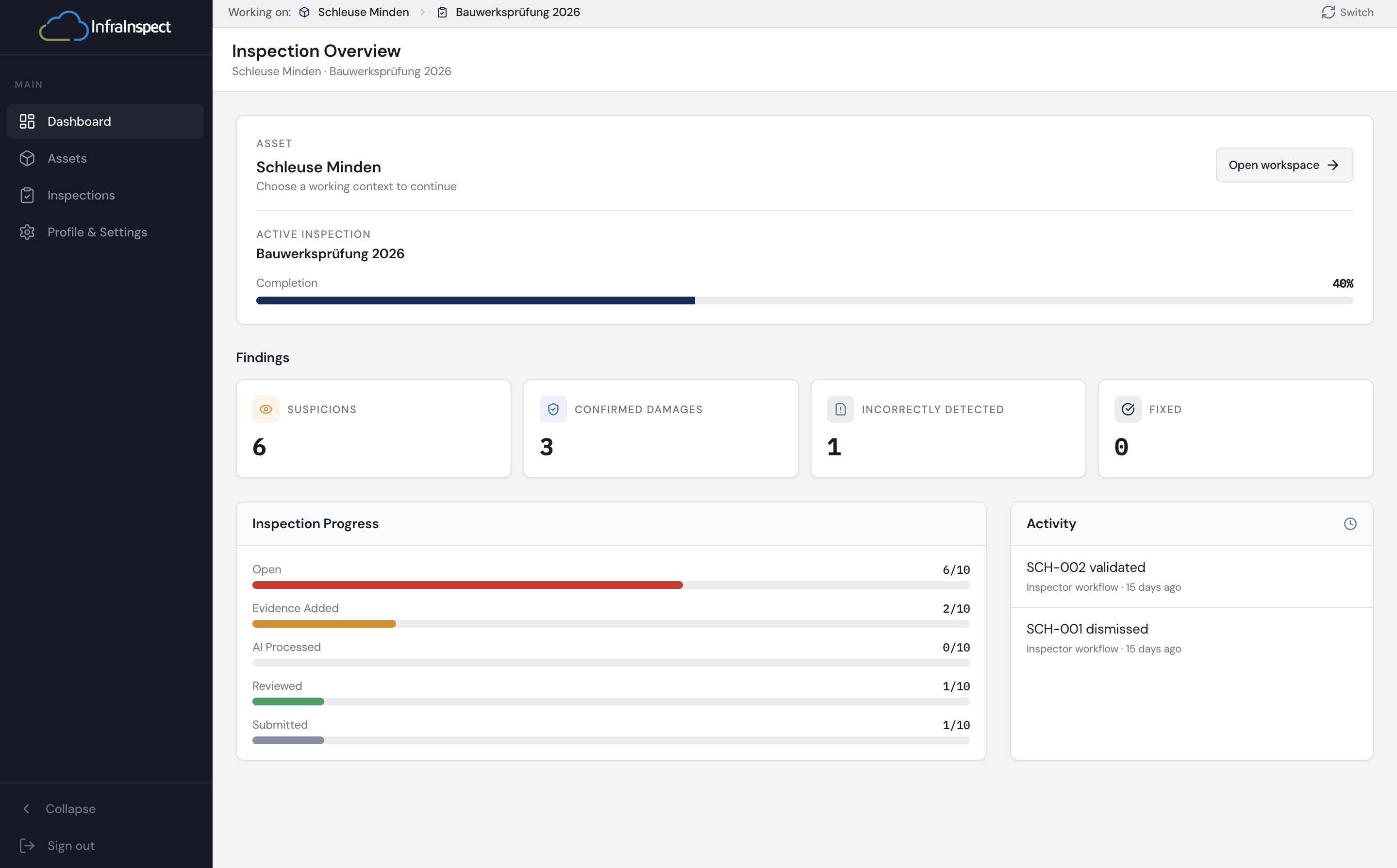
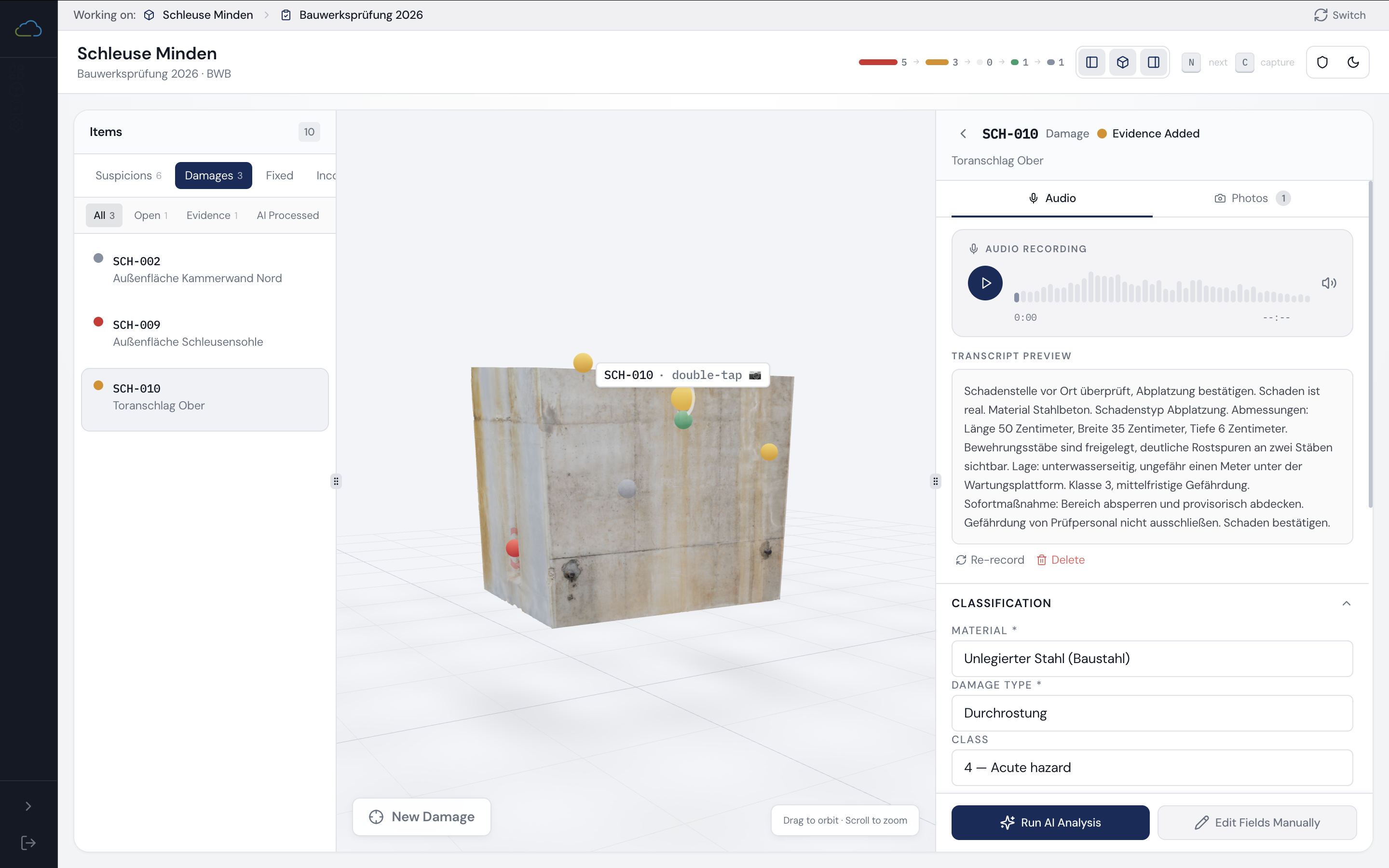
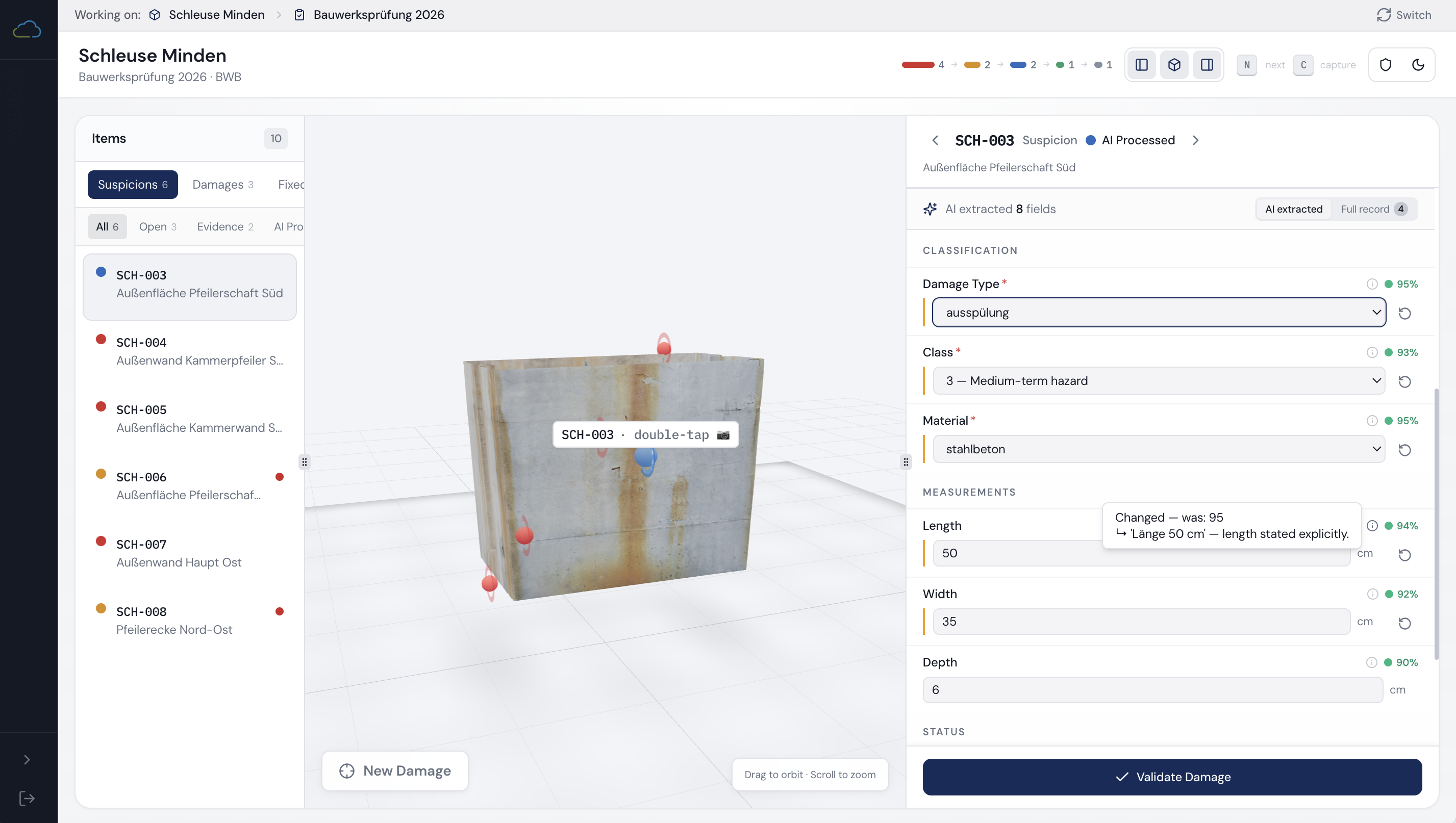
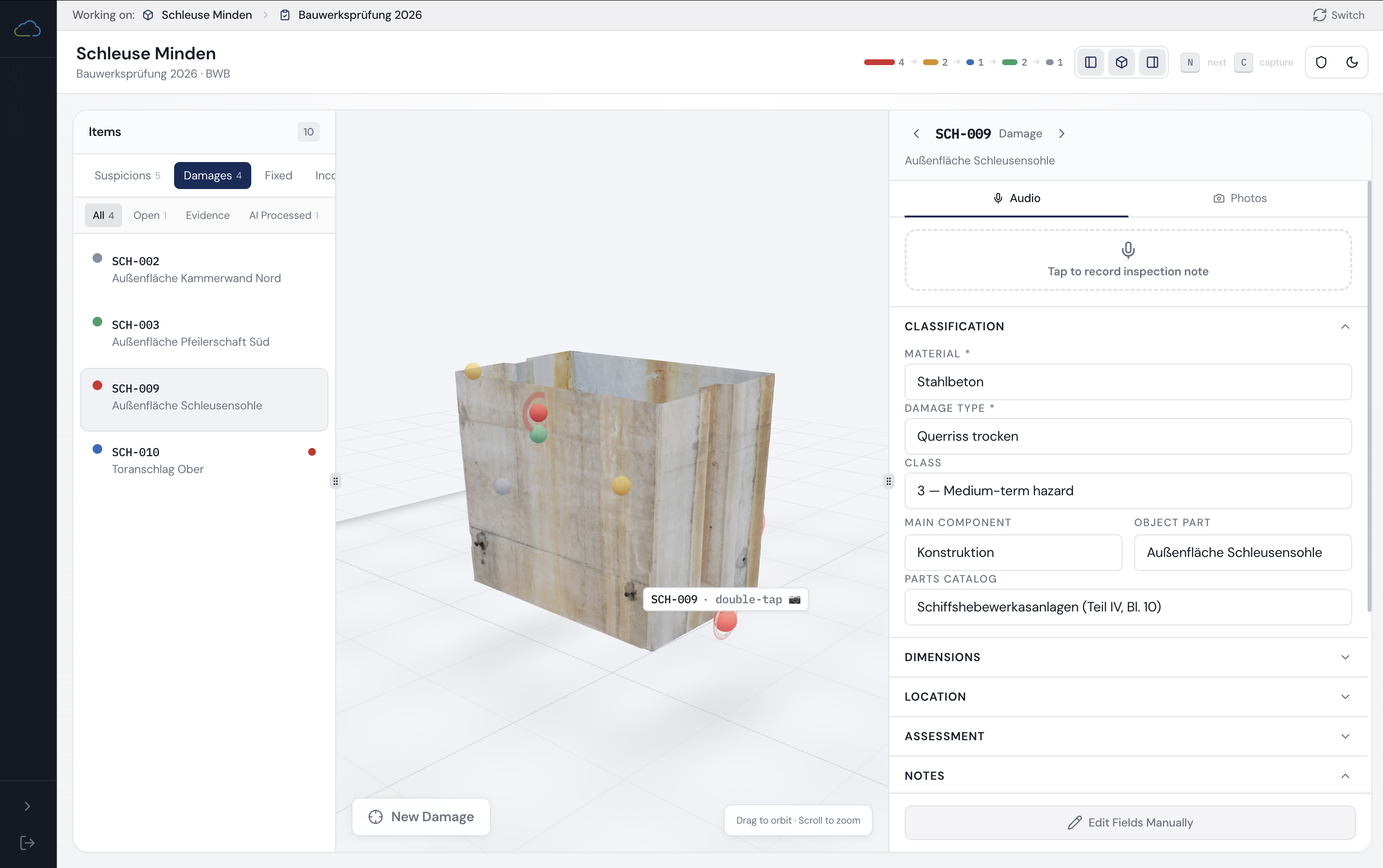
HydroMapper's InfraCloud platform centralises inspection data, 3D context, and structured damage records for water infrastructure: quay walls, harbours, bridges, hydraulic structures, and underwater assets. The platform worked. The field documentation workflow didn't match the realities of high-volume on-site inspection.
InfraCloud is web-based, not optimised for mobile, and requires substantial manual input for every damage record. In practice: one person inspects, another enters findings manually. Under real field conditions: bad weather, generator noise, poor connectivity, underwater work, the process becomes slow, error-prone, and fragile.
The core challenge was not identifying damages. It was capturing structured inspection data faster, more reliably, and with less manual effort, across two very different working contexts: the office, where damage suspicions are planned and reviewed against 3D models, and the field, where the same person is standing in front of a quay wall in bad weather with no free hand. Bridging those two contexts without disrupting either shaped every decision in this project.