The first design decision was what the AI should and shouldn't do. The pipeline has 17 nodes. The LLM is called in exactly two of them: once to pick the next data action during collection, once to frame the evidence per ticker in plain language. Everything else (scoring, anomaly detection, personalisation, alert checking, persistence, delivery) is deterministic Python. That boundary wasn't accidental. It made the pipeline testable, the costs predictable, and the output debuggable: when a signal is wrong, you know which node produced it.
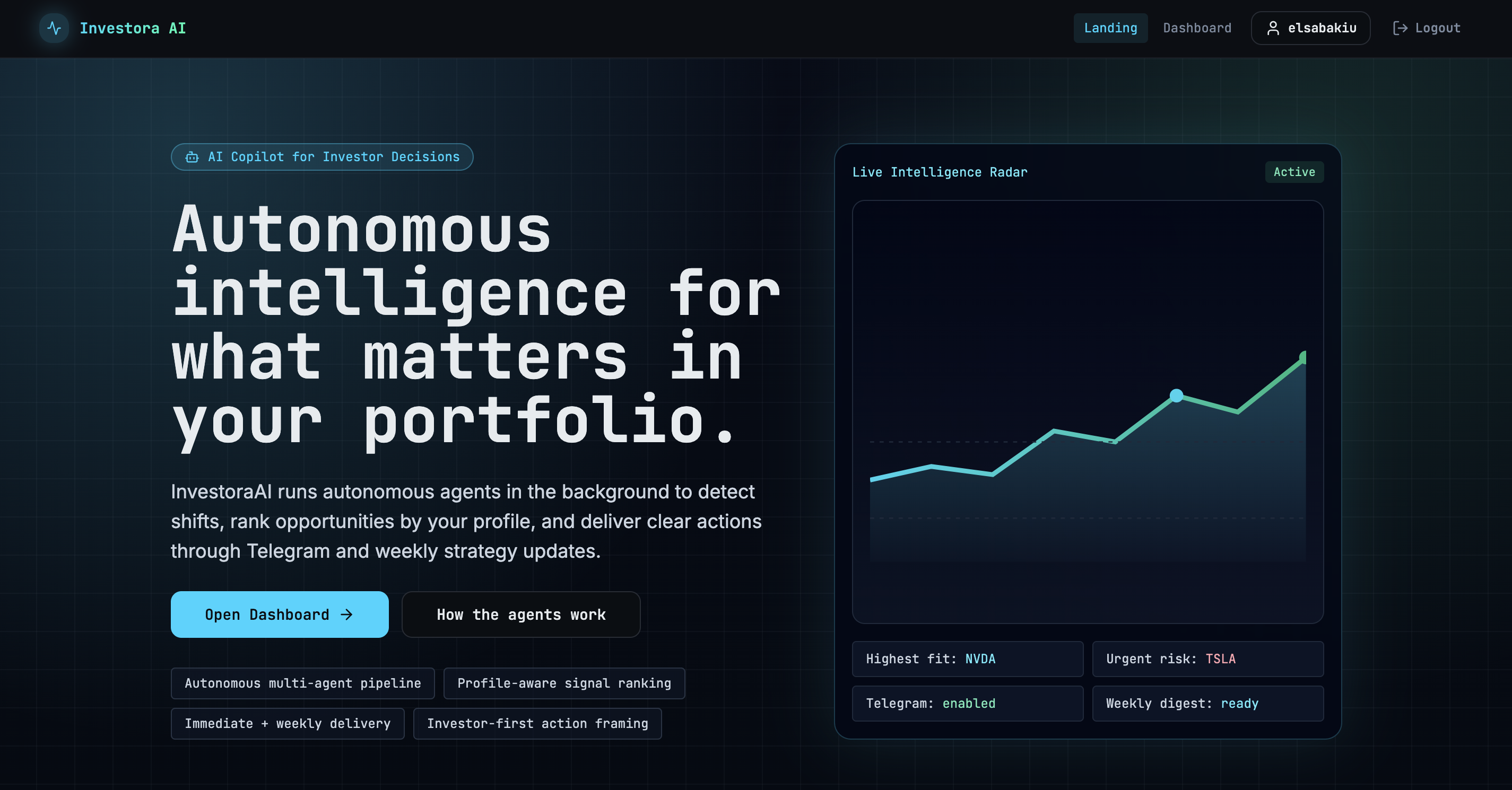
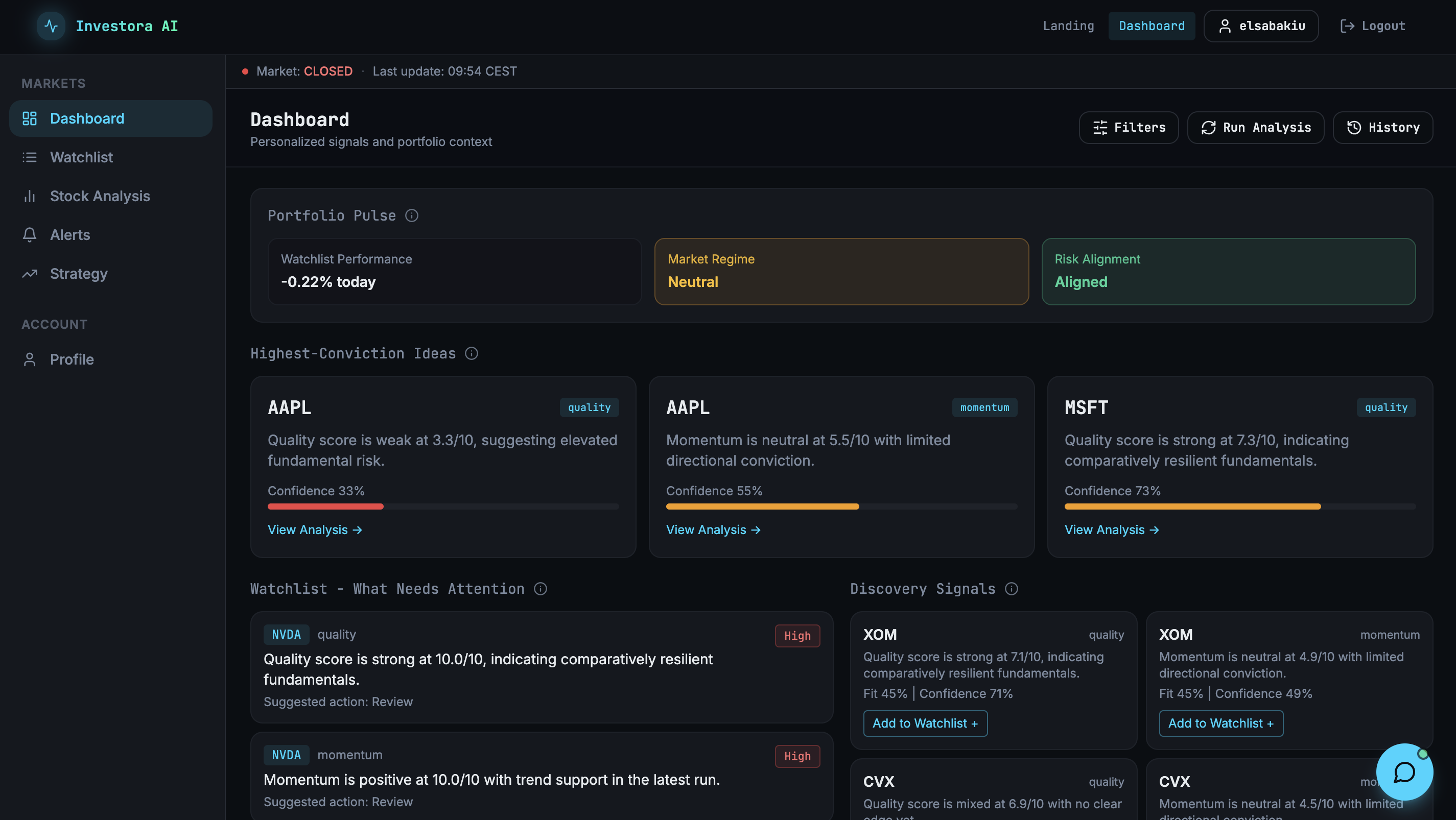
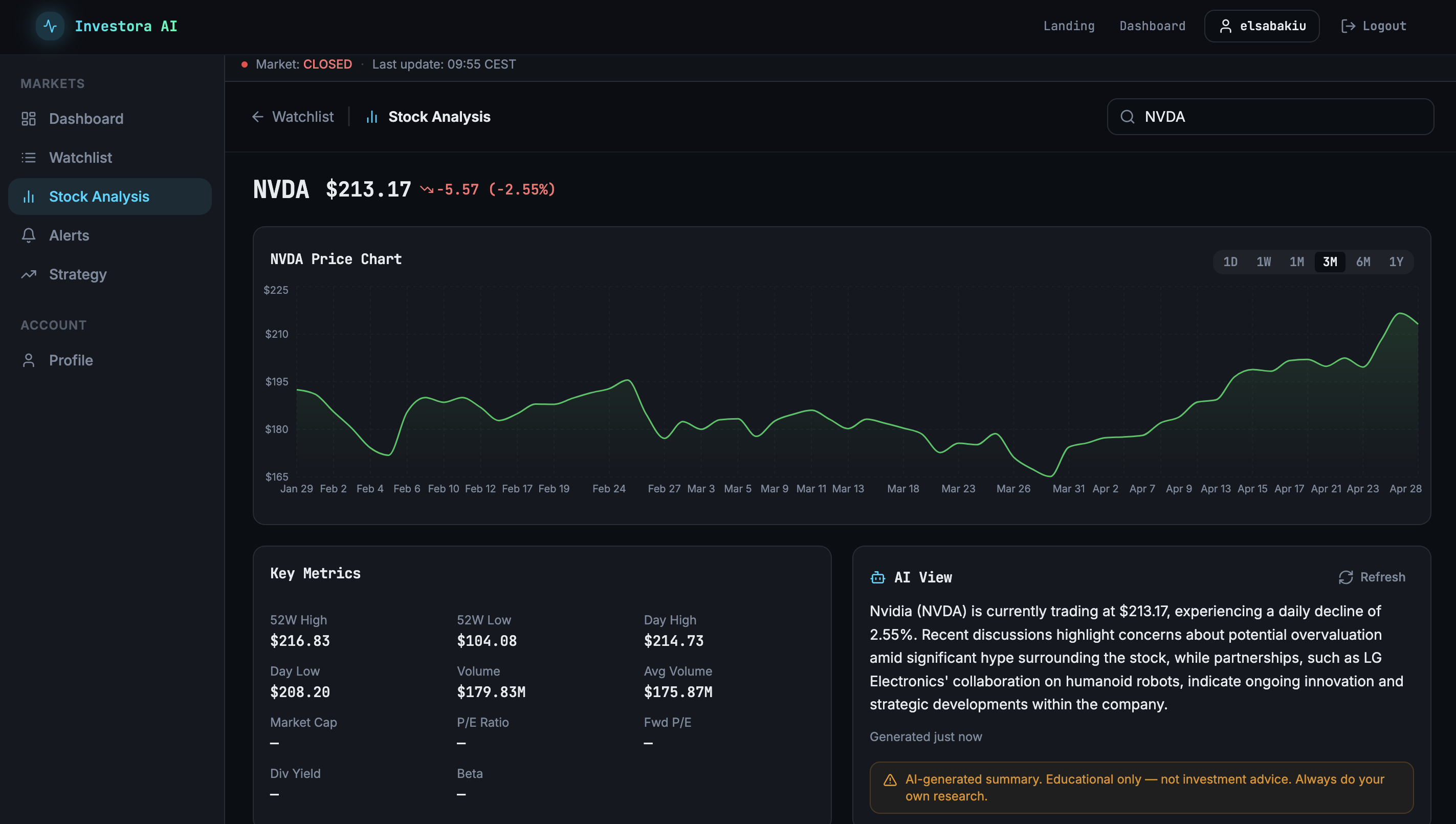
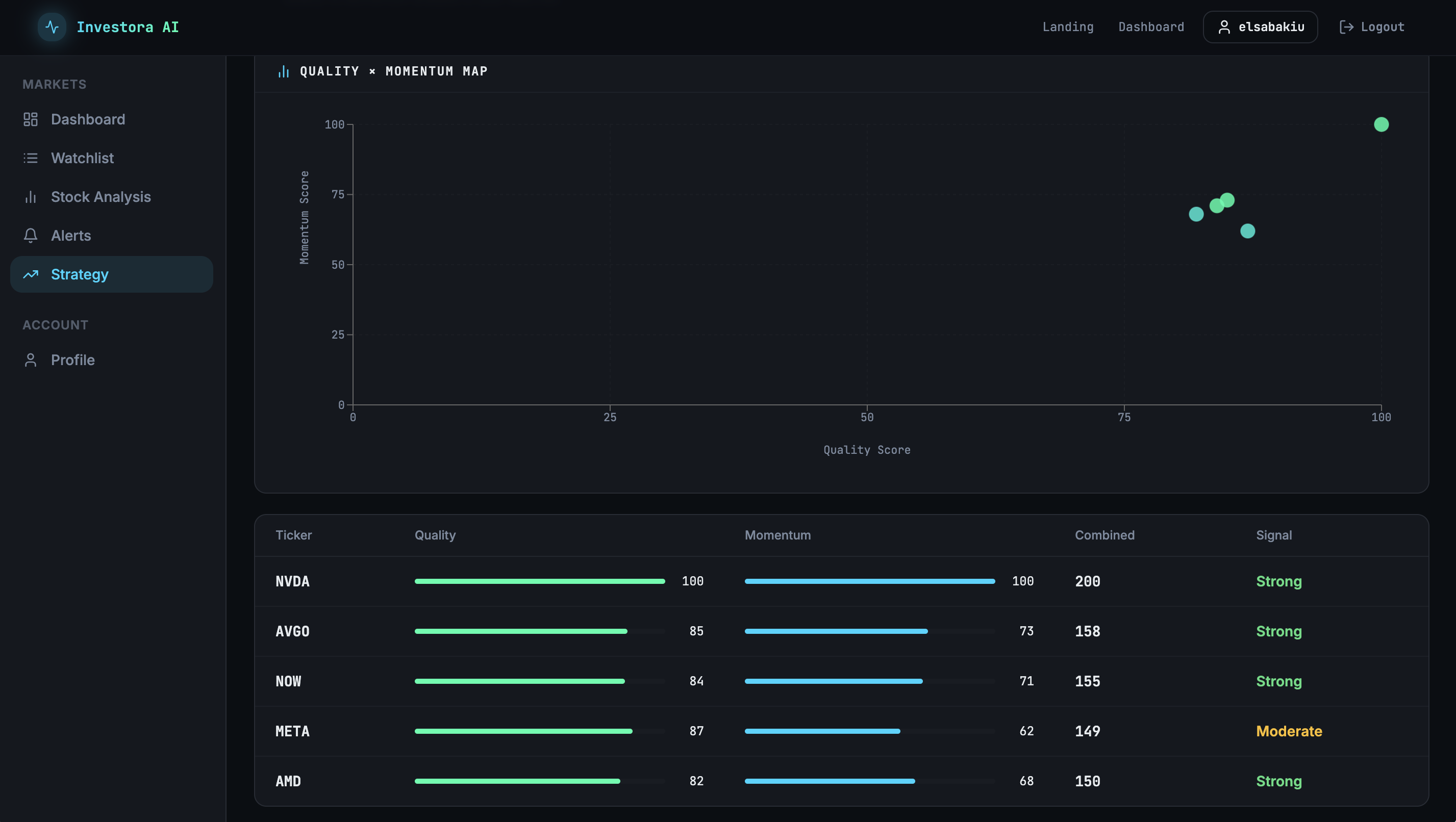
Scoring is transparent by design. Quality comes from three fundamentals dimensions: profitability (return on equity, operating margin), balance-sheet health (debt-to-equity), and growth (revenue and earnings growth), each normalised to a 0–10 range and blended with fixed weights. Momentum is the 5-day closing price return, normalised across the ticker universe. The two combine at 55/45 in favour of quality, a deliberate preference for medium-horizon signals over swing-trade noise. The weights live in environment variables, not in a prompt.
Personalisation operates on three axes: whether the ticker is on the user's watchlist (binary, always highest priority), how well the signal fits their stated profile (sector interests, asset class preferences, investment horizon), and whether it clashes with their risk tolerance. The third axis is what drives mismatch alerts: a high-severity signal for a low-risk user surfaces explicitly rather than quietly disappearing. No user asks for this. It's the most opinionated feature in the product, and the one most likely to be genuinely useful.
Two notification families ship from the same pipeline run. The weekly digest is gated: it fires only when the run is full-scope and the user has opted in with a confirmed email. When the gate passes, a webhook triggers an n8n workflow that renders a formatted HTML email with that week's ranked candidates. Telegram alerts are different: they fire during every eligible run and cover two independent subtypes. High-urgency personalised signals (severity flagged as High by the personalisation layer) bypass the weekly cadence and post immediately. User-defined price alerts check explicit thresholds the user configured (price above, price below, daily move beyond a percentage) against the fresh quote data already fetched in that run. Both types share one design principle: delivery is soft-fail. If the Telegram webhook errors or the email workflow fails, the exception is caught and appended to the run's error log: the analysis still persists to the database and the dashboard still updates. Pipeline success is never coupled to notification delivery.